
Security agencies leak sensitive data by failing to sanitize PDF files
Security agencies are doing a poor job at sanitizing PDF documents they publish on their official websites and are leaking troves of sensitive information that could be collected and weaponized in malware attacks.
In a research paper published this month, the French National Institute for Research in Computer Science and Automation (INRIA) said it collected and analyzed 39,664 PDF files published on the websites of 75 security agencies from 47 countries.
INRIA researchers Supriya Adhatarao and Cédric Lauradoux said they were able to recover sensitive data from 76% of the files they analyzed. This included data such as:
- Name of the author
- Name of the PDF app
- Operating system
- Device details
- Author email
- File path information
- Comments and annotations
19 security agencies didn't update software for 2+ years
The researchers warn that threat groups could collect documents from an agency's website over time and build profiles on the agency's software policy and individual employee machines.
"For instance, we found one employee of a security agency who has never changed or updated his/her software during a period of 5 years," said Adhatarao and Lauradoux.
"We found at least 19 security agencies in our dataset who are using the same software over a period of 2 years or more."
"This kind ofinformation is particularly interesting for a hacker to target an individual with bad software habits," the researchers said.
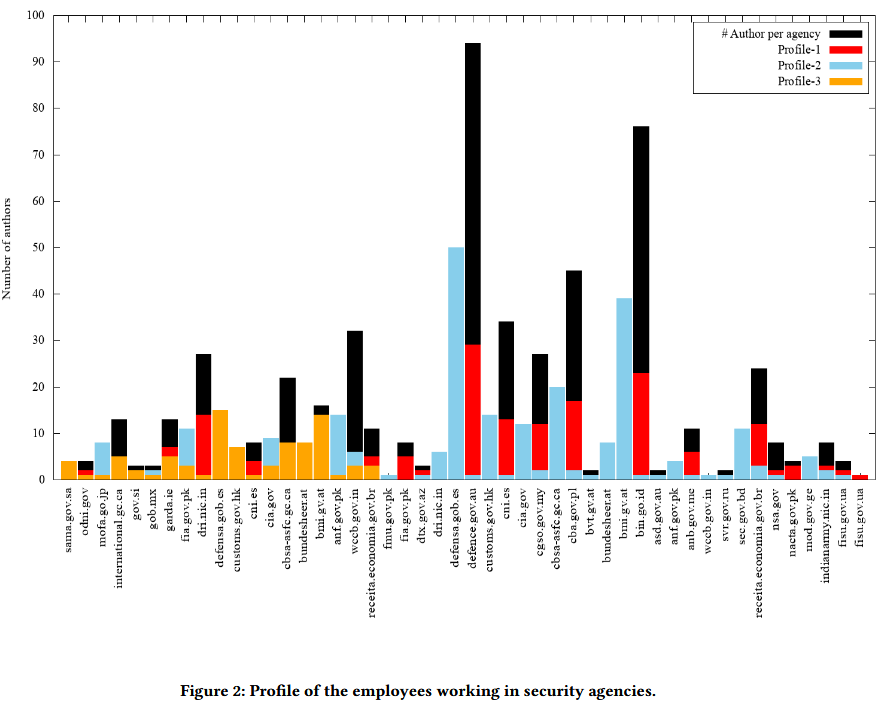
Adhatarao and Lauradoux said that of the 75 security agencies they studied, only 38 had a software policy in place and were regularly updating their software.
Only three security agencies sanitized PDF files properly
However, even if agencies sanitized their PDF documents to remove metadata and other authoring artifacts, the sanitization process was not up to par to standards and sometimes left usable data behind.
According to the researchers, only seven of 75 agencies were sanitizing PDF documents, but, in reality, only three were removing all sensitive data.
PDF sanitization should not be confused with the process of redaction.
Redaction hides text from a reader at the document text level, while sanitization removes data from the file itself, such as metadata and document properties.
In the late 2000s, after a series of diplomatic scandals, the NSA published a guide on proper e-document sanitization, recommending the removal of information such as the ones in the list below, before a file could be published and made available to the general public:
1. Metadata
2. Embedded Content and Attached Files
3. Scripts
4. Hidden Layers
5. Embedded Search Index
6. Stored Interactive Form Data
7. Reviewing and Commenting
8. Hidden Page, Image, and Update Data
9. Obscured Text and Images
10. PDF Comments (Non-Displayed)
11. Unreferenced Data
Security agencies and other government organizations which fail to remove this data from their public documents expose themselves to attacks. Open-source tools, like FOCA, allow threat actors to easily collect this information.
Additional details are available in an INRIA paper titled "Exploitation and Sanitization of Hidden Data in PDF Files."



Catalin Cimpanu
is a cybersecurity reporter who previously worked at ZDNet and Bleeping Computer, where he became a well-known name in the industry for his constant scoops on new vulnerabilities, cyberattacks, and law enforcement actions against hackers.