

Microsoft 365, Cloudflare say service restored after outages
Microsoft said a day-long service outage affecting the Exchange Online service has ended following hours of complaints from users about connection issues.
On Monday evening, Microsoft explained that it was investigating problems with the service after users said they were “experiencing delays or connection issues when accessing the Exchange Online service.”
Two hours later, the company said its traffic management infrastructure was not working and attempted to reroute traffic in an effort to end the outage.
It took another nine hours before service was fully back to normal.
“Rerouting traffic combined with targeted infrastructure restarts has successfully restored service access and functionality,” the company said in a series of tweets on Tuesday.
Rerouting traffic combined with targeted infrastructure restarts has successfully restored service access and functionality. Please refer to EX394347 and MO394389 in the Microsoft 365 admin center for additional details.
— Microsoft 365 Status (@MSFT365Status) June 21, 2022
Microsoft urged users to look through notes in the Microsoft 365 admin center for more information about the situation.
Users reported having severe issues logging into Exchange Online mailboxes and sending emails.
Others reported issues with Microsoft Teams, Universal Print, SharePoint Online and the Graph API.
The problems came at the same time as a wide-ranging service outage affecting Cloudflare that started early on Tuesday morning.
Users on several platforms -- including Amazon, Telegram, Discord, Coinbase, Twitch, Amazon Web Services, DoorDash, Steam and more -- reported having problems gaining access.
In a blog about the issue, Cloudflare said the outage affected traffic at 19 data centers that handle significant portions of its traffic.
A whole bunch of internet infrastructure just went down all at once…? pic.twitter.com/2FImDTIJGK
— Fuck Elon Musk (parody) (@HackingButLegal) June 21, 2022
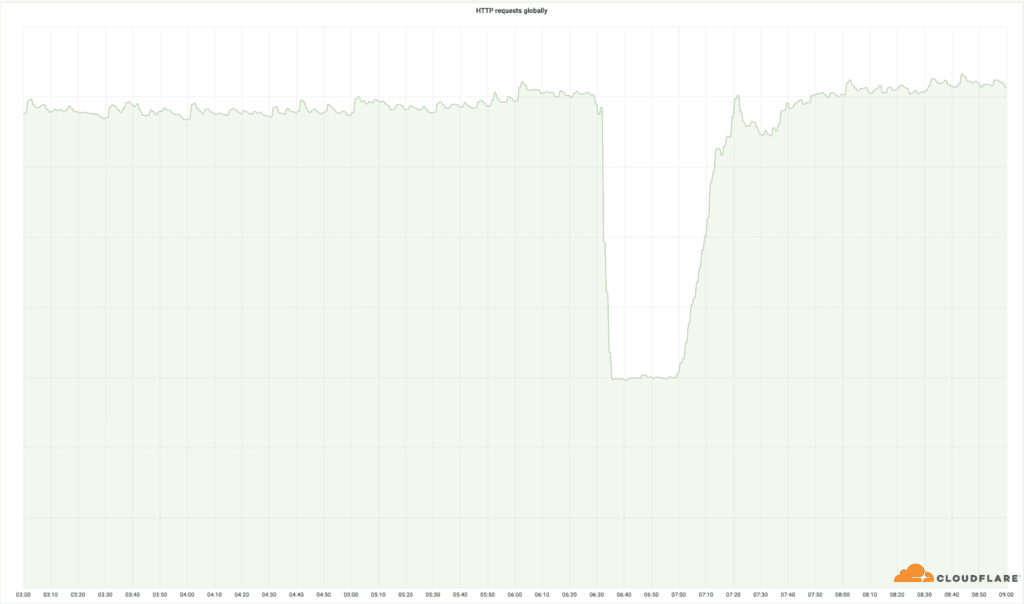
“This outage was caused by a change that was part of a long-running project to increase resilience in our busiest locations. A change to the network configuration in those locations caused an outage which started at 06:27 UTC,” Cloudflare explained.
“At 06:58 UTC the first data center was brought back online and by 07:42 UTC all data centers were online and working correctly. Depending on your location in the world you may have been unable to access websites and services that rely on Cloudflare. In other locations, Cloudflare continued to operate normally. We are very sorry for this outage. This was our error and not the result of an attack or malicious activity.”
The blog goes on to explain that the company was attempting to convert data centers in Amsterdam, Atlanta, Ashburn, Chicago, Frankfurt, London, Los Angeles, Madrid, Manchester, Miami, Milan, Mumbai, Newark, Osaka, São Paulo, San Jose, Singapore, Sydney, Tokyo to a “more flexible and resilient architecture.”
Cloudflare said that while these locations represent just 4% of its total network, the outages affected 50% of the total HTTP requests it handles globally.



Jonathan Greig
is a Breaking News Reporter at Recorded Future News. Jonathan has worked across the globe as a journalist since 2014. Before moving back to New York City, he worked for news outlets in South Africa, Jordan and Cambodia. He previously covered cybersecurity at ZDNet and TechRepublic.